Back when I was employed researching the mysteries of the universe by pipetting lots of stuff, I used to say that physics was the study of things that are pointy in the middle and small on the ends, so that we can ignore the ends. Essentially, the idea in much of science is to figure out how to boil a phenomenon down to a few variables that have reasonably well defined values, i.e., a mean or average value. All measured variables have a distribution, but not all distributions are pointy in the middle, and only for distributions that are pointy in the middle does it make sense to calculate the average value. As a classic counterexample, the power-law distribution doesn't have a pointy middle:

You can still, of course, calculate the mean value of this distribution by summing over all the values and dividing by the number of values. But the point is that it won't mean much intuitively: "most" of the values won't be "around" the mean value. They're all over the place. So, if we want to be able to talk about measuring a "variable", we'd like it to have a peak in the middle. In particular, it would be really handy if our distribution was a Normal Distribution (aka, the famous Bell Curve, or Gaussian, after the legendary mathematician and physicist Carl Freidrich Gauss.)

A normal distribution has a couple of very nice properties that make math a lot easier:
Luckily for us, the Central Limit Theorem has our back. What it says, basically, is that if you take a whole bunch of random variables, what you get out will probably* be pretty close to a normal distribution. And this is good news for people who like things high in the middle and flat on both ends**. Most real processes in the world are the result of a bunch of sub-processes, each of which has its own distribution. For instance, the average number of fish in a lake may depend on the average rainfall, the average temperature, the average number of fisherman, and the average amount of food, each of which in turn is affected by a number of other variables. When we mush these all together, things tend towards a normal distribution, which lets us deal with most natural processes in a tractable way mathematically, giving us a universe in which many things of interest have well defined average values, because they're peak-y.
*Without getting too deep in the weeds, this is true assuming your distributions have both a finite mean and a finite variance. Some power-law distributions do not have a finite variance, because they have what's called a "fat tail": basically, they don't converge to zero fast enough, so there's lots of stuff way out towards infinity. If all your variables are like this, you're in trouble. Luckily for us, the real world is mostly composed of things that have finite variance.
**As opposed to Ohio, which is high in the middle and round on both ends.

You can still, of course, calculate the mean value of this distribution by summing over all the values and dividing by the number of values. But the point is that it won't mean much intuitively: "most" of the values won't be "around" the mean value. They're all over the place. So, if we want to be able to talk about measuring a "variable", we'd like it to have a peak in the middle. In particular, it would be really handy if our distribution was a Normal Distribution (aka, the famous Bell Curve, or Gaussian, after the legendary mathematician and physicist Carl Freidrich Gauss.)
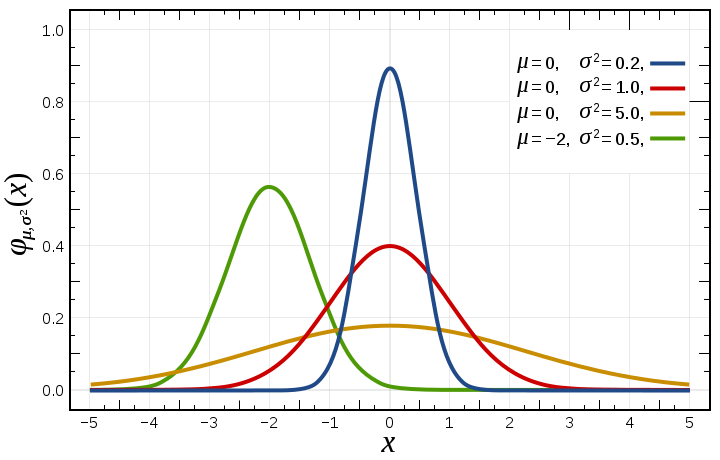
A normal distribution has a couple of very nice properties that make math a lot easier:
- The mean, median, and mode are all the same.
- It's mathematically tractable to work with and has a simple form.
Luckily for us, the Central Limit Theorem has our back. What it says, basically, is that if you take a whole bunch of random variables, what you get out will probably* be pretty close to a normal distribution. And this is good news for people who like things high in the middle and flat on both ends**. Most real processes in the world are the result of a bunch of sub-processes, each of which has its own distribution. For instance, the average number of fish in a lake may depend on the average rainfall, the average temperature, the average number of fisherman, and the average amount of food, each of which in turn is affected by a number of other variables. When we mush these all together, things tend towards a normal distribution, which lets us deal with most natural processes in a tractable way mathematically, giving us a universe in which many things of interest have well defined average values, because they're peak-y.
*Without getting too deep in the weeds, this is true assuming your distributions have both a finite mean and a finite variance. Some power-law distributions do not have a finite variance, because they have what's called a "fat tail": basically, they don't converge to zero fast enough, so there's lots of stuff way out towards infinity. If all your variables are like this, you're in trouble. Luckily for us, the real world is mostly composed of things that have finite variance.
**As opposed to Ohio, which is high in the middle and round on both ends.
No comments:
Post a Comment